How I find the best resources about Scrapy using Google BigQuery

In this post, I would talk about how I find the best packages and resources about Scrapy using Google BigQuery, and I wish it can help you or inspire you to find gold in your area.
Intro
As a tech writer who has published many tutorials about Scrapy, I have received many messages from my readers asking help. Sometimes I am surprised to find out that actually someone has done similar job before and we can directly import the project into our scraping project. However, it seems there is no good article or project helping people to find the best packages or resources from Scrapy community, that is why I decided to do the work and published it as awesome-scrapy, a curated list about Scrapy.
The method talked about in this article can also be used in another tech area, so I would be glad if you can learn something from this article.
Where to find high-quality apps and resources about Scrapy
Considering Scrapy is written in Python and is an open source project on Github, after brainstorming, I decided to find high-quality resources from places below, and metrics in the parentheses is used to help me find good resources.
- Github (Star Number)
- Pypi (Download Number)
- Google (Page Rank)
Explore Github
At first, I go to Explore page of Github to search Scrapy and set the filter to Most stars.
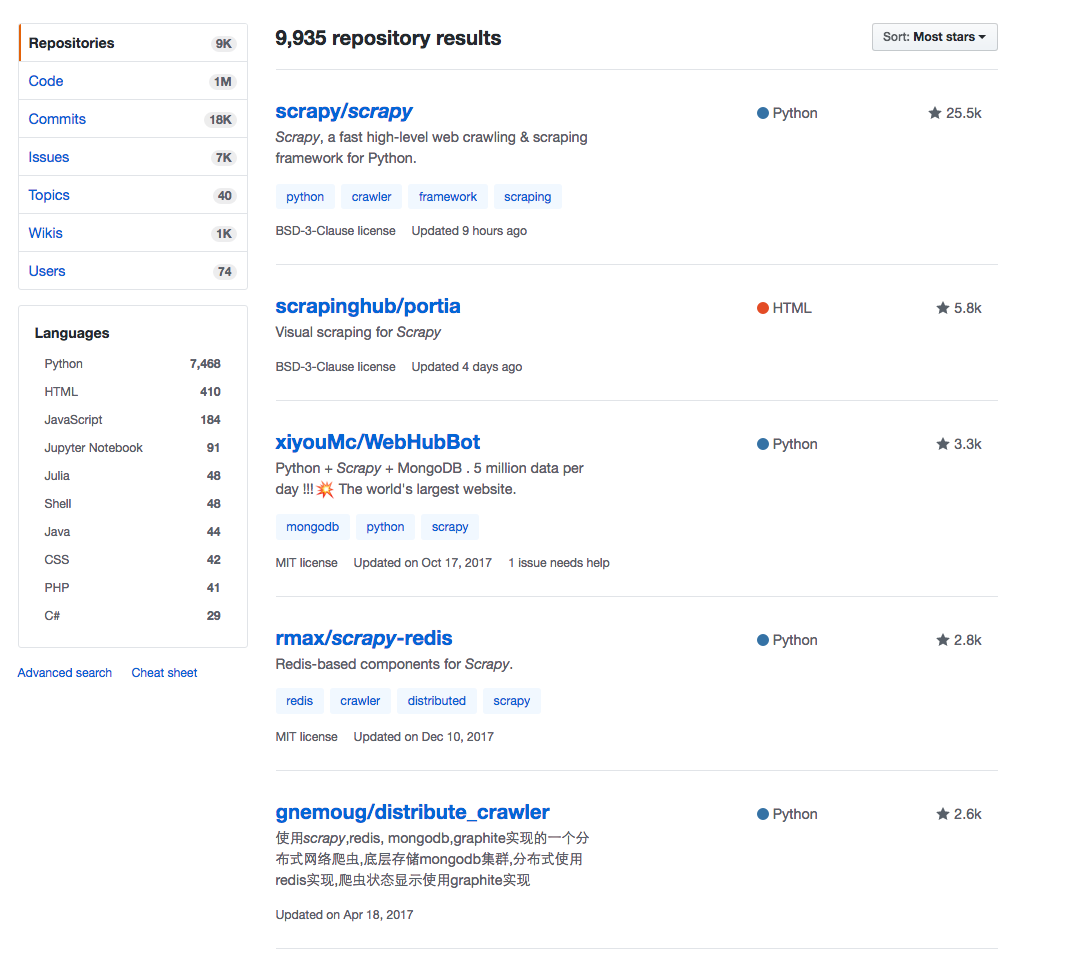
I found it is time-consuming to check and copy the content from web pages manually, so I decided to write a spider to automate the process.
I wrote a simple Python script using BeautifulSoup to download the title, URL, description, stars from the URL above, it also processed the pagination. To avoid crawling too many pages, the spider would stop if the star of the project is less than 100.
The data scraped is saved to a CSV file, so I can open it locally using Excel to review. I will talk about how I process the data in a bit.
The spider was done in minutes, so I moved to next step.
Explore Pypi
Let me clarify first if you are not familiar with Python community.
Pypi is a Python package index where people can publish, search and download Python package. It is like npm in Javascript community.
I also searched Scrapy in Pypi and wrote a spider to collect data just like what I did on Github.
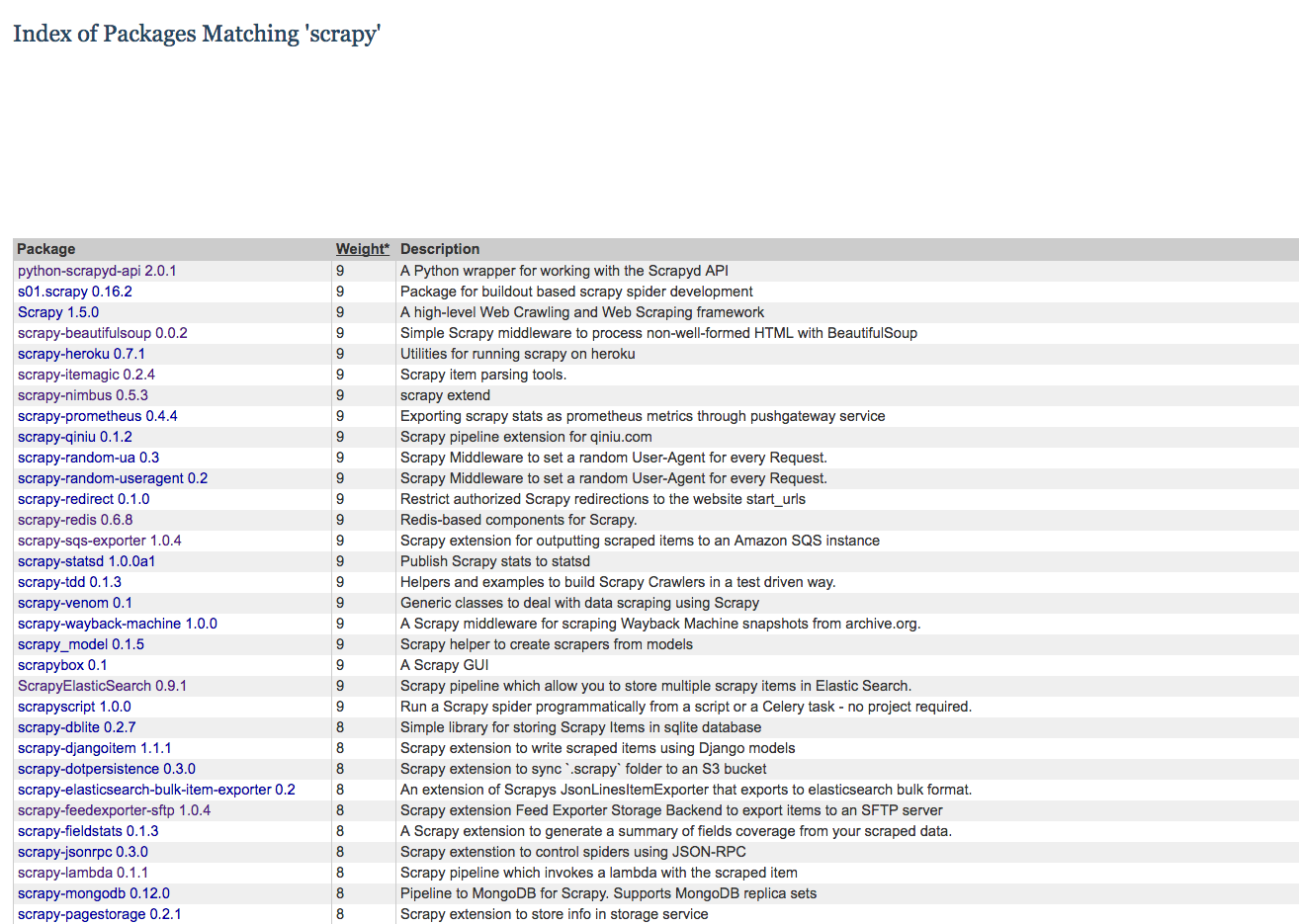
Unlike Github, there is no star number in Pypi, so I decided to get the monthly download count to help me decide which package is high-quality. I thought user behavior would give me the answer.
I reviewed some package on Pypi, but did not find download stats, so I asked Google for help.
I got answer from a blog post, which told me Pypi has removed download stats from the web page and now Google BigQuery can be used to get the download stats. Somebody has created a project pypinfo on Github so I can use it directly. Oh, I love Github!
Now I start to write python script again.
-
The script would crawl package data such as title, description, URL from the search result page of Pypi, the scraped data is saved to a csv file.
-
Then I used
pypinfoto get the download stats of all packages of csv and updated the file.
Analyze Data
Now I have many packages from Github and Pypi in hand, I need quickly find high quality packages from dozens of packafges. First, I should find a way to filter out some low quality packages.
-
I found many packages from GitHub are Scrapy spiders to crawl websits in China such as Weibo, Douban, Taobao, I removed them because they are not reusefble but just some spiders.
-
Pypi packages which have low download stats have been removed.
-
At last, I have no useful tool but my brain, so I started to review packages in Excel. I thought many packages from Pypi should also be hosted on Github, so reviewing Github data is my first step.
I spent about one hour to finally find about 30 packages which are all great projects relevant with Scrapy, and I believe Scrapy beginners can benefit a lot from this project. They do not need spend so much time to search and review when facing problem.
What is my next step.
It seems there is no good automated way to help me find good resources about Scrapy from Google, so I plan to add article in spare time.
Now I have many good packages in awesome-scrapy, In the next weeks, I can add article talking about the packages. For example, talking about how to build a distributed web crawlwer using Scrapy-redis.
If you have any good idea, I would appreciate that if you could share it with me.
Some notes about Google BigQuery I want to share with you

Because I do not fully understand Google BigQuery work in this case, so I did some research again and below is what I found.
In 2016, Pypi has started to use Google BigQuery, it insert the download data into a dataset located on Google Platform (Every downlaod request receieved by Pypi is saved to the dataset). BigQuery can make people use a SQL-like languate to analyze the big data, which is very helpful to handle this situation.
SELECT COUNT(*) as download_count
FROM TABLE_DATE_RANGE(
[the-psf:pypi.downloads],
TIMESTAMP("2018-01-20"),
CURRENT_TIMESTAMP()
)
WHERE file.project="django"
As you can see, code above query download count of Django package on 2018-1-20, If you have wrote SQL I am pretty sure you can soon understand and write your own. pypinfo talked above is just like a wrapper to do the same thing.
So if you want to use BigQuery in your project, first, you should add data to a data table. Second, you can start to write query statement to analyze the data, the biggest advantage is the speed.
So here I have question, the Github task in this post can also be done using Google BigQuery? The answer is Yes, check this page GitHub Data, you can try to use it as you like.
And I have found other intesting resources for you to play. Hacker News Data, Stack Overflow Data.
One thing still bothering me is that Google said "first TB of queried data each month is free. Each additional TB is $5.", but I still do not fully undersantd how to calculate the queried data and how to estimate the cost of using BigQuery.
If somebody can help me make it clear, that would be great!
Conclusion
In this article, I talked about how to find high quality packags and resources about Scrapy, I wish this article can also inspire you to find more good resources you are interested. What is more, I tried using Google BigQuery to help me analyze data in an efficient way, I must say this experience is amazing, and I recommende you to give it a try.
Resources
Pypi Publicly Queryable Statistics